
Introduction
Google’s LightweightMMM and Meta’s Robyn stand out as prominent open- source automated Marketing Mix Modeling (MMM) tools, each with the noble aim of democratizing econometrics and marketing science. Despite a shared objective, the two tools diverge significantly in their approaches, implementations, and overarching paradigms. This article undertakes a comprehensive comparison, delving into various facets such as implementation methodologies, modeling techniques, optimization strategies, documentation quality, and community support.
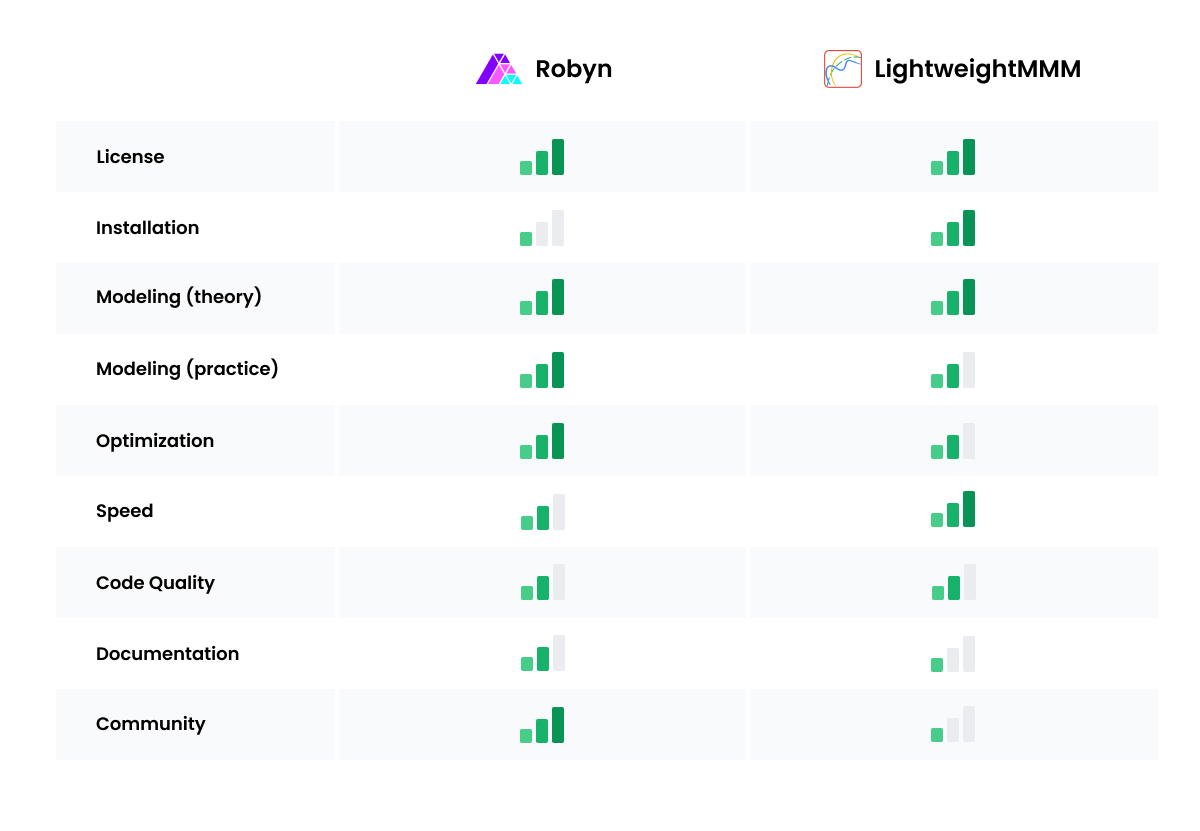 Quick comparison table: Meta Robyn vs LightWeightMMM
Quick comparison table: Meta Robyn vs LightWeightMMMLicense
While the terms "open source" and "free" are occasionally used interchangeably, it’s crucial to note that they don't always carry the same meaning. However, in the context of LightweightMMM and Robyn, these terms align. Both libraries come with licenses permitting modification, distribution, private use, and commercial use. A distinction lies in the licenses themselves: Robyn opts for the MIT License, which doesn't impose restrictions on trademark use, whereas LightweightMMM operates under the Apache License 2.0, which does include such restrictions.
Another noteworthy difference is Robyn’s apparent openness to external contributors, evident in a dedicated section within their documentation guiding individuals on how to contribute to the codebase—a feature not found in LightweightMMM. To sum it up we can say that both libraries are free to use.
Implementation
Google’s LightweightMMM presents itself as a remarkably user-friendly Python library , seamlessly integrating with Google’s latest machine learning framework , JAX. Since the introduction of their renowned TensorFlow framework in 2015 , Google has consistently been a trailblazer in the realm of open-source machine learning and data science. However , facing formidable competition—most notably from PyTorch by Meta—TensorFlow encountered challenges , including significant design flaws , resulting in a gradual shift in Google’s focus.
In response, Google embarked on a fresh journey, gradually moving away from TensorFlow and embracing JAX, a new machine learning framework they introduced. Alongside this transition, they developed novel tools such as LightweightMMM, signaling a commitment to innovation in the field. It's noteworthy that the choice of JAX brings flexibility and efficiency to LightweightMMM, enhancing its capabilities
In the evolving landscape of data science, the influence of Meta’s PyTorch framework has been pronounced. This impact is evident in LightweightMMM’s probability distribution module, which heavily relies on the Numpyro framework. Notably, Numpyro’s documentation explicitly acknowledges its design inspiration from PyTorch, showcasing the cross- pollination of ideas and techniques in the dynamic field of machine learning frameworks.
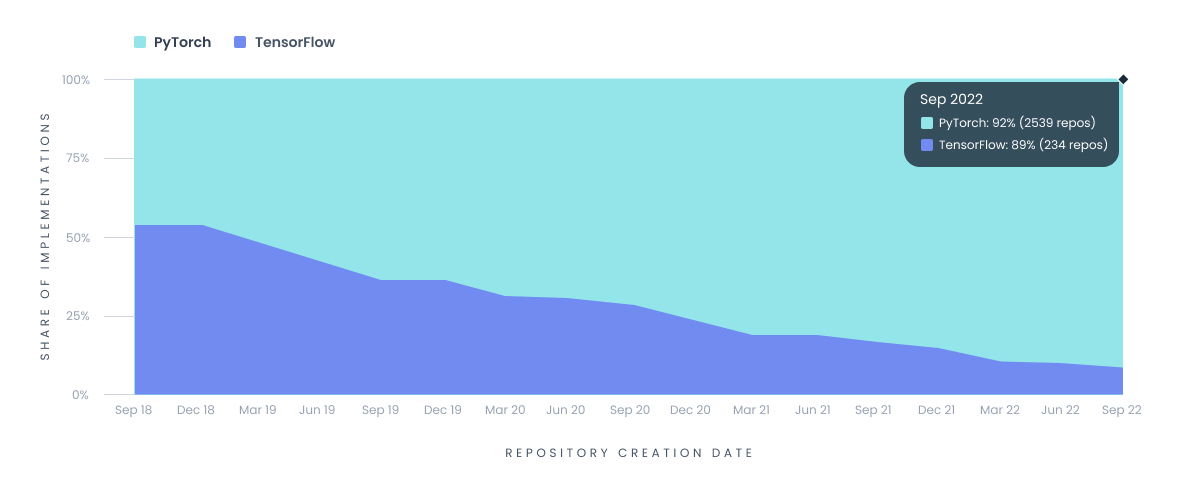 Installation share: PyTorch vs TensorFlow
Installation share: PyTorch vs TensorFlowMeta’s Robyn emerges as a library implemented in the R programming language, albeit with a notable requirement for a parallel Python installation. This dual-language dependency introduces challenges in terms of installation, maintenance, and software deployment. The intricacies involved in managing the integration of both R and Python components may present hurdles for users.
The core of Robyn’s forecasting capabilities draws on Meta’s Prophet library, implemented in R. Notably, the optimization module within Robyn leverages the Python library Nevergrad, also a creation of Meta. This fusion of R and Python elements adds a layer of complexity to the library’s architecture.
Interestingly, the choice to develop Robyn in R may raise questions, especially given that Prophet, the underlying forecasting tool, has a Python implementation. The rationale behind this decision remains somewhat unclear, as it introduces an additional layer of complexity with the need for Python integration. The potential advantages or specific reasons for selecting R as the primary implementation language for Robyn, especially when Python alternatives are available, would be a subject of interest for users seeking a more streamlined and unified environment for their data science workflows.
LightweightMMM holds a notable advantage over Robyn in its ability to leverage GPU hardware for accelerated model training. This advantage stems from LightweightMMM’s foundation on the JAX framework, which efficiently harnesses the power of GPUs. This capability contributes to significantly faster model training times, enhancing the overall efficiency of the process.
On the other hand, Robyn takes a different approach to optimize performance. Its optimization module, powered by Nevergrad, implements techniques that lend themselves to embarrassingly easy parallelization of computations. This strategic use of parallelization serves to expedite the computational processes within Robyn, particularly in the context of optimization. The emphasis on optimization, a critical aspect in many data science workflows, underscores Robyn’s commitment to efficiency and speed, albeit through a different technical avenue.
In summary, LightweightMMM gains an edge by tapping into GPU acceleration for model training, courtesy of JAX, while Robyn focuses on optimizing computation through parallelization techniques, facilitated by Nevergrad, particularly in its optimization module. The choice between these advantages would depend on specific user preferences, hardware availability, and the nature of the data science tasks at hand.
Modeling
The methodologies adopted by LightweightMMM and Robyn in the context of Marketing Mix Modeling (MMM) exhibit distinct differences. Robyn, in particular, adheres to a frequentist approach, in contrast to a Bayesian perspective. Its modeling strategy entails treating marketing phenomena as a "curve fitting" problem, employing the Prophet library. Despite some potential confusion within the MMM community about the Bayesian aspects, Prophet primarily utilizes a frequentist approach, specifically implementing a Generalized Additive Model (GAM). In this approach, time series are conceptualized as compositions of additive components, including trend, seasonality, holidays, and noise.
While it’s worth noting that Prophet might utilize Bayesian methods, such as Markov Chain Monte Carlo (MCMC), for estimating uncertainty bands, the core modeling of time series is fundamentally non-Bayesian. Prophet's design is centered around the GAM framework, providing a structured approach to capturing various components influencing time series data.
An essential advantage of adopting the Prophet library within Robyn lies in its convenience and efficiency. Prophet comes pre-equipped with holidays for numerous countries, streamlining the modeling process by incorporating these predefined factors directly. This feature enhances the usability of Robyn in scenarios where accounting for holidays is a crucial aspect of the MMM process.
In summary, Robyn takes a frequentist approach to MMM, utilizing the Prophet library, which is grounded in the GAM framework. The library's provision of predefined holidays for multiple countries contributes to its appeal for marketers seeking a practical and accessible MMM solution. Robyn’s adoption of a curve-fitting approach brings forth several advantages. The simplicity of curves facilitates easy decomposition, and the parameters derived from the fitting process carry straightforward interpretations. Moreover, the efficiency of this approach contributes to a fast and streamlined modeling process.
 Visualisation of curve-fitting approach
Visualisation of curve-fitting approachIt’s crucial to address certain criticisms directed at Prophet’s forecasting abilities within the machine learning community. However , these critiques may not be entirely relevant in the context of Robyn. Unlike some applications of Prophet for future inference, Robyn utilizes Prophet primarily for fitting and decomposing existing data. The fitting process involves minimizing the square of the prediction error, a concept dating back to Gauss in 1795, commonly known as the Least Squares Fit or, simply, 'linear regression.'
While this approach is straightforward, there is a potential risk of overfitting, particularly in scenarios with a high number of independent variables and a limited number of samples or observations. Robyn employs a regularization technique, specifically Ridge Regression, to address this concern. Regularization involves penalizing the coefficients of the linear fit, preventing excessively high magnitude coefficients and mitigating the risk of overfitting. Ridge Regression, although a linear model, introduces a square penalty to achieve this regularization.
In the broader context, frequentists, as seen in Robyn’s approach, often frame problems in terms of cost functions—the metric to be minimized— rather than incorporating probability distributions based on domain knowledge or past experience (referred to as 'priors'). This distinction reflects the philosophical differences between frequentist and Bayesian approaches to statistical modeling.
The decision to employ a linear model in the context of marketing, despite the inherently non-linear nature of phenomena like the law of diminishing returns, is driven by the numerous benefits associated with linear models. The interpretability of fitted parameters, ease of decomposition, and computational efficiency make linear models, such as those used in Ridge Regression within Robyn, attractive choices.
To address the non-linear aspects of marketing phenomena, a clever strategy is employed. Rather than abandoning the simplicity of linear models, the input data undergo certain non-linear transformations. These transformations may include saturation curves, adstock, and other techniques aimed at capturing the non-linearities inherent in the marketing domain. This approach allows for the retention of the advantages associated with linear models while accommodating the complexities of non-linear relationships within the data.
The Ridge Regression formula, as documented in Robyn, reflects this approach. By applying regularization techniques to the linear model, Robyn mitigates the risk of overfitting and accommodates non-linear patterns through the transformed input data. This combination of linear modeling and non-linear transformations strikes a balance between simplicity and flexibility, optimizing the modeling process for the intricacies of marketing dynamics.
LightweightMMM’s commitment to Bayesian modeling in Marketing Mix Modeling (MMM) introduces a paradigm shift, emphasizing a probabilistic framework over traditional frequentist methods. This approach is characterized by the modeling of all parameters as probability distributions, allowing for a more nuanced understanding of the uncertainties inherent in marketing phenomena. One key advantage lies in the capacity for users to integrate their past experiences and expectations as prior distributions, aligning the model more closely with real-world insights.
The Bayesian framework not only enables the incorporation of subjective insights but also provides genuine probabilistic interpretations of uncertainty. This nuanced perspective is invaluable in the dynamic landscape of marketing, where risk assessment and understanding the variability associated with different strategies are essential for effective decision-making.
However, the practical implementation of Bayesian modeling, as seen in LightweightMMM, requires a balance. While the tool offers the capability to specify detailed prior distributions, such as the Lewandowski-Kurowicka-Joe distribution implemented in the LKJCholesky function in Numpyro, it acknowledges the challenges. The expectation of digital marketing experts to navigate and articulate such intricate statistical details may indeed be a stretch.
Nevertheless, LightweightMMM stands out by providing a powerful tool that caters to a spectrum of users. For those with the expertise and inclination to delve into the Bayesian framework, it offers a unique avenue to infuse detailed domain knowledge into MMM models. This flexibility positions LightweightMMM as a valuable asset in the toolkit of marketers and data scientists, allowing them to tailor their modeling approaches to their specific needs and expertise levels.
Optimization: Robyn
The optimization processes in Robyn and LightweightMMM demonstrate notable distinctions. In Robyn , optimization encompasses various aspects of the modeling process , specifically focusing on hyper-parameter selection for non-linear adstock transformations. For instance , the geometric adstock transformation introduces three hyper-parameters for tuning , while the Weibull transformation introduces four for each media variable.
The optimization procedure in Robyn serves the dual purpose of minimizing the Ridge Regression fit and optimizing a novel metric termed Decomp.RSSD. This metric is designed to measure the deviation of the model from the current spend allocations. By incorporating this novel metric , Robyn aims to incentivize the model to identify solutions that not only minimize the Ridge Regression fit but also align more closely with plausible scenarios , avoiding abrupt deviations from current marketing spend allocations.
What sets Robyn apart is its emphasis on incrementality in the optimization process. The model is iteratively calibrated , taking into account ground truths obtained from experiments. This iterative approach contrasts with a fixed tuning approach , highlighting a commitment to continuous refinement based on evolving data and experimental insights. The focus on incrementality in model calibration reflects a dynamic and adaptive approach , making Robyn responsive to real-world changes in marketing dynamics.
Robyn’s optimization strategy relies on the Nevergrad Python library, a name cleverly coined to signify that the optimization methods are not gradient-based, eliminating the need for calculating gradients (commonly referred to as 'slope') during the optimization process. The wordplay suggests a departure from traditional gradient-based optimization methods. Nevergrad proves to be an excellent choice for Robyn’s optimization needs. Leveraging evolutionary algorithms, Nevergrad offers a parallelizable approach, enhancing computational efficiency. Additionally, the library allows for the incorporation of arbitrary constraints, providing flexibility for tech-savvy users who may wish to tailor the optimization scheme to specific requirements.
However, it’s important to note that the high number of hyper-parameters associated with optimizing adstock in Robyn does result in a comparatively slower computational process. This is in contrast to LightweightMMM, where the optimization process may proceed more swiftly, potentially due to a lower number of hyper-parameters or other design considerations.
The trade-off between computational speed and the complexity of optimization is a common consideration in the design of MMM tools, and the choice of Nevergrad in Robyn reflects a preference for robust and flexible optimization methods, even if it comes at the cost of increased computational time.
Optimization: Lightweight MMM
LightweightMMM opts for the Scipy Python library to perform budget optimization. In contrast to Nevergrad , Scipy’s optimization algorithm , Sequential Least Squares Quadratic Programming (SLSQP) , is a gradient- based method. This means that the optimization involves calculations of gradients (slopes) during the iterative process.
However, it’s worth noting that the documentation for both Robyn and LightweightMMM acknowledges a common challenge: the convergence metrics and warnings provided by these optimization processes may not be easily interpretable or actionable for non-computer scientists. This underscores a common issue in optimization procedures, where the technical details of convergence may not provide clear insights for users who are not experts in optimization algorithms.
The choice of optimization method , whether gradient-based like SLSQP or evolutionary like Nevergrad, often involves trade-offs between computational efficiency and ease of interpretation. While LightweightMMM benefits from Scipy’s well-established optimization capabilities, the challenge of translating optimization metrics into actionable insights for non- experts remains a broader consideration in the field of optimization within data science tools.
Documentation: Robyn
- The source code in Robyn is reported to contain unused and commented- out sections , which could indicate incomplete or outdated features.
- Documentation for Robyn is noted to be more comprehensive , offering in- depth information about the library and its functionalities.
Documentation: LightweightMMM
- The source code in Robyn is reported to contain unused and commented- out sections , which could indicate incomplete or outdated features.
- However , there might be areas where improvements can be made in adherence to best practices for scalable software development.
In summary , while LightweightMMM is perceived to have better code quality , Robyn excels in terms of documentation depth. The prioritization of development speed in Robyn , at the expense of robustness , is noted as a potential concern leading to backward compatibility issues. These considerations highlight the trade-offs and areas for improvement in both libraries concerning software development practices.
Community
In the realm of community engagement , Robyn emerges as a clear leader. The presence of an active Facebook group , the "Robyn Open Source MMM Users ," dedicated to transparent roadmaps and discussions around Project Robyn , provides users with a vibrant platform. This community space allows users to pose questions , seek assistance in analyzing results , and gain insights into new feature requests.
The peer-to-peer network established by Robyn’s community is identified as a significant advantage. With developers actively participating in discussions , posting updates on Robyn’s next development priorities , and offering assistance , users can readily access valuable information and support. This active engagement fosters a sense of reassurance , knowing that answers to questions are readily available through posts or existing discussions on the platform.
Furthermore , the GitHub issues/bug tracker for Robyn is noted to be significantly more active compared to LightweightMMM. This suggests a high level of community involvement in reporting issues , suggesting improvements , and contributing to the overall development and enhancement of the Robyn library.
In summary , Robyn’s community engagement stands out , providing users with a dynamic platform for discussions , support , and insights into the development roadmap. The active participation of developers and the robust GitHub activity contribute to the strength of the Robyn community.
Summary
It’s fascinating to see the landscape of Marketing Mix Modeling (MMM) being shaped by R&D teams from tech giants through open-source frameworks. Both LightweightMMM and Robyn , despite not being production-ready applications , offer powerful tools for MMM. Their open-source nature fosters community collaboration and innovation in the field.
The different paradigms and approaches they take highlight the diversity and richness within the MMM community. The fact that they cater to different perspectives and methodologies can be seen as a positive aspect , providing users with choices that align with their preferences or specific requirements.
As of the current stage , your observation that Robyn seems slightly ahead in terms of democratizing marketing science is noteworthy. This could be attributed to factors such as the robust community engagement , in-depth documentation , and the active involvement of developers in addressing user needs and advancing the tool’s capabilities.
It’s always exciting to witness the evolution of such tools and how they contribute to advancing marketing science. The competition and diversity in approaches within the open-source MMM ecosystem ultimately benefit the entire community by providing a range of options for users with different use cases and preferences.
